So I just added this to our copyright notice on the epub version:
No AI tools were used to assist in writing this work.
The use of this work to train any AI is forbidden.
Because of this tweet right here:
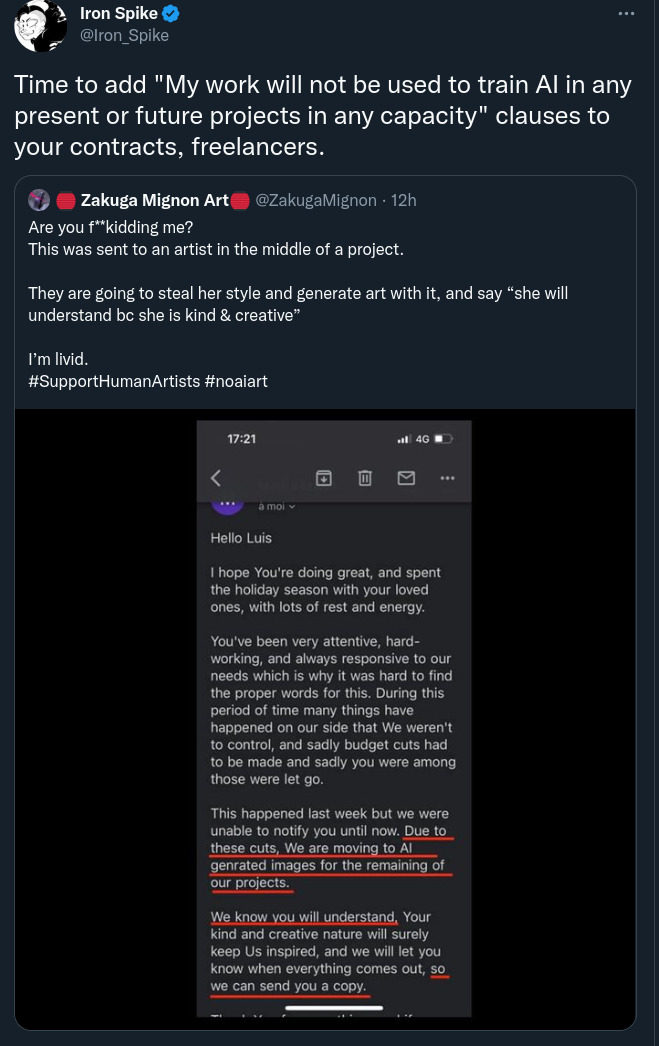
I’m surprised at my reaction. I’ve been up to my neck in technology forever. I make my living with advanced technology. ChatGPT is fascinating, as are the new set of audio and visual tools. Not to mention real life use in protecting computers and property. Properly used, AI is amazing.
Then some moron at a corporation comes along and makes the downside crystal clear. We don’t want to pay you, but you’ve given us enough to train an AI, so we can just continue “in your style”. That’s possible now. Generally consulting contracts are “Works for hire” and usually the output is owned by the creator unless expressly signed over in a contract. However, once it’s signed over, what happens if it’s used to train an AI to make more of your style?
The implications for freelancers, visual artists, writers, and musicians are unbelievable. We’ve reached a point where a voice AI can be trained using about 3 minutes of your voice, and do a fair job of copying you.
A couple of things to note legally – first only human-generated content is eligible for copyright. Even if a human edits an AI generated work, then it’s a derivative work, and only the edited portions added by the human are copyrightable.
The US Patent and Trademark office has a good explanation of this here.
For businesses wanting to use AI generated content – a reminder: That work isn’t copyrightable, and anyone can copy and use it.
For artists creating content where some sort of contract is involved, like a work for hire, a book with its implicit contracts, possibly even web pages or apps with terms of service – consider the implication of someone training an AI to do your style of creation.
Consider Val Kilmer being able to “speak” after throat cancer – by licensing his voice for AI use. All these creations are now licensable assets to be ingested by a machine somewhere. Don’t give those rights away. If you’re going to allow your work to be used as part of AI, negotiate that right.
Similarly – a declaration of AI non-use tells readers, this is the genuine article created by this author. You’re getting the real deal.
Of course we’ve been down this road before. I’m sure with the advent of photography, visual artists freaked out, ditto audio recording. These technological advancements ended up making creators wealthy by vastly expanding their audiences.
Perhaps creators will become weathy and famous by providing training sets for AIs. And maybe genuine human-made art will demand a premium. Or non-AI generated content will become more popular, just because there’s a human involved.
Or vice-versa. The machines win.
Being a creator is hard enough, but we’re about to enter the era of AI powered conmen and spammers.
p.s Vice just published this which reads in part: about an artist banned from Reddit’s largest art subreddit:

“I don’t believe you,” a moderator for r/art replied. “Even if you did ‘paint’ it yourself, it’s so obviously an Al-prompted design that it doesn’t matter. If you really are a ‘serious’ artist, then you need to find a different style, because A) no one is going to believe when you say it’s not Al, and B) the AI can do better in seconds what might take you hours. Sorry, it’s the way of the world.”
But the artists are fighting back – Protecting Artists from AI Technologies is a gofundme… and they’re trying to get the laws changed… from the site:
Stability AI funded the creation of the biggest and most utilized database called LAION 5B. The LAION 5B database, originally created on the pretext of “research” contains 5.8 billion text and image data, including copyrighted data and private data, gathered without artists, individuals, and businesses’ knowledge or permission. [Sean’s Note: looking at the LAION site, it’s clear there’s a lot of real research happening, and imagine if google had to get your permission to index things. Commerical use of the results is really the issue.]
MidJourney, Stability AI, Prisma AI (Lensa AI) & other AI/ML companies are utilizing these research datasets that contain private and copyrighted data, for profit. They did so without any individual’s knowledge or consent, and certainly without compensation.
We are not anti-tech and we know this technology is here to stay one way or another but there are more ethical ways that these models can co-exist with visual artists. This is what we will be proposing these future models look like:
- Ensure that all AI/ML models that specializes in visual works, audio works, film works, likenesses, etc. utilizes public domain content or legally purchased photo stock sets. This could potentially mean current companies shift, even destroy their current models, to the public domain.
- Urgently remove all artist’s work from data sets and latent spaces, via algorithmic disgorgement. Immediately shift plans to public domain models, so Opt-in becomes the standard.
- Opt-in programs for artists to offer payment (upfront sums and royalties) every time an artist’s work is utilized for a generation, including training data, deep learning, final image, final product, etc. AI companies offer true removal of their data within AI/ML models just in case licensing contracts are breached.
- AI Companies pay all affected artists a sum per generation. This is to compensate/back pay artists for utilizing their works and names without permission, for as long as the company has been for profit.
Finally, a Princeton student just created GPTzero which promises “Efficient detection of AI generated text. So we have a decent chance at identifying our overlords, until they change their algorithm.
The AI battle is heating up.