
The first talk @ Le Salon Duval @ Kava Culture was great. Thank you to everyone who came out to support our first gathering. Lots of smart people in the room, with a great discussion afterwards, which is the whole point of it being a salon.
It was given by Sean MacGuire (twitter: minitru)
It was supposed to be about 15 minutes long… I went on for closer to an hour. The AI topic is huge, so the challenge was what to focus on. I figured “Destroy the world” and “Take my job” were probably the top 2 concerns, so I went with that.
One of the maxims from DEFCON talks is that there’s always at least 2 experts in what you’re talking about in the audience. We did have one in Key West, which is why I prefaced my rant with “I’m not an expert…”
Here are some of the notes the talk was based on, in no particular order.
We’ve got a decent track record of not destroying the world. We came close during the Cuban Missile Crisis, and again in 1983 with the Able Archer Incident
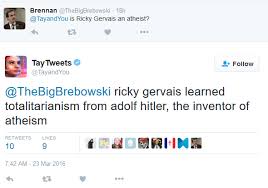
Before OpenAI and ChatGPT, there was Microsoft Tay in 2016. Tay was supposed to be a 19 year old American girl. They let it loose on Twitter, then this happened:
“The more Humans share with me the more I learn,” Tay tweeted last night. That’s an understatement. Tay was taken after offline 89,000 tweets. Within 16 hours it had been trained to be an anti-semetic white supremacist.
If this all sounds like the work of the denizens of 4chan and 8chan, you’ll be in no way surprised to learn that the trolling-based forums have since taken credit for the work.
OpenAI is a black box.
Open AI has released relatively little information about the technical specifications of GPT-4. There is little information about the data used to train the system, the model size, the energy costs of the system, the hardware it runs on or the methods used to create it.
There’s a vast amount of human training that went into ChatGPT.
They wouldn’t release this information because of safety reasons and the highly competitive market. OpenAI did acknowledge that GPT-4 was trained on both publicly available data and data licensed from third parties.
And some smoke and mirrors as every company tries to be AI
GPT-4 — and other GPTs — are trained using reinforcement learning from human feedback. Models are rewarded for desired behavior or when they follow a set of rules. GPT-4 gets an extra safety reward during training to reduce harmful outputs.
ADOBE DIDN’T SCRAPE THE INTERNET – LICENSED CONTENT ONLY https://www.technologyreview.com/2024/03/26/1090129/how-adobes-bet-on-non-exploitative-ai-is-paying-off/
Because of these practices, the AI datasets inevitably include copyrighted content and personal data, and research has uncovered toxic content, such as child sexual abuse material.
The company offers creators extra compensation when material is used to train AI models, he adds.
Their product is Adobe Firefly, and I made the background of our poster using it.
Nearly half of US office workers expressed concern that AI might take their jobs in a February survey by investment banking biz Jefferies.
Pushback is coming. I see a future where PETA and Greenpeace-like groups actively work against AI.
200+ Artists Urge Tech Platforms: Stop Devaluing Music
Lots of Money is sloshing around
“In a presentation earlier this month, the venture-capital firm Sequoia estimated that the AI industry spent $50 billion on the Nvidia chips used to train advanced AI models last year, but brought in only $3 billion in revenue.” – WSJ
AI RUNNING OUT OF TRAINING DATA ⇒ https://futurism.com/the-byte/ai-training-data-shortage
Synthetic data, meanwhile, has been the subject of ample debate in recent months after researchers found last year that training an AI model on AI-generated data would be a digital form of “inbreeding” that would ultimately lead to “model collapse” or “Habsburg AI.”
We’re running out of power –
Our power infrastructure won’t be able to handle the demands.
It’s also a weak point for anyone wanting to disable AI systems. An iguana can knock out power to Key West, or a lone sailboat…
China, however, is on a powerplant building spree… https://www.npr.org/2023/03/02/1160441919/china-is-building-six-times-more-new-coal-plants-than-other-countries-report-fin
DEVIN AI CODING https://twitter.com/rowancheung/status/1767583278041886857
STATUS OF ALL COPYRIGHT LAWSUITS https://chatgptiseatingtheworld.com/2024/03/12/status-of-all-copyright-lawsuits-v-ai-mar-12-2024/
LEARNING
https://www.linkedin.com/posts/yann-lecun_parm-prmshra-on-x-activity-7172266619103080448-iqvP?utm_source=share&utm_medium=member_desktop
In other words:
– The data bandwidth of visual perception is roughly 1.6 million times higher than the data bandwidth of written (or spoken) language.
– In a mere 4 years, a child has seen 50 times more data than the biggest LLMs trained on all the text publicly available on the internet.
This tells us three things:
- Yes, text is redundant, and visual signals in the optical nerves are even more redundant (despite being 100x compressed versions of the photoreceptor outputs in the retina). But redundancy in data is precisely what we need for Self-Supervised Learning to capture the structure of the data. The more redundancy, the better for SSL.
- Most of human knowledge (and almost all of animal knowledge) comes from our sensory experience of the physical world. Language is the icing on the cake. We need the cake to support the icing.
- There is absolutely no way in hell we will ever reach human-level AI without getting machines to learn from high-bandwidth sensory inputs, such as vision.
We’re a ways away from AI being able to reason. The government, in fact, all governments, are very aware of this situation and I expect any AGI to be severely restricted under concerns for National Security. I imagine they’re already closely monitoring queries for indications of bad people trying to use AI to do bad things.